GAN
Generative Adversarial Nets
1. introduction
在对抗网络框架中,生成模型与对手进行竞争:
一个判别模型,该模型学习确定样本是来自模型分布还是来自数据分布。
生成模型可以被认为类似于一组伪造者,试图制造假币并在不被发现的情况下使用,而判别模型类似于警察,试图检测假币。这个游戏中的竞争促使两队改进他们的方法,直到假货与正品无法区分。
在本文中,我们探讨了生成模型通过多层感知器传递随机噪声生成样本的特殊情况,而判别模型也是多层感知器。 我们把这种特殊情况称为对抗性网络。
在这种情况下,我们可以只使用非常成功的反向传播和dropout算法来训练这两个模型,并且只使用正向传播从生成模型中采样。不需要近似推理或马尔可夫链。
2. Adversarial nets
当模型都是多层感知器时,对抗性建模框架最容易应用。
为了学习生成器在数据 \(x\) 上的分布 \(p_g\) ,我们定义了输入噪声变量 \(p_z(z)\) 的先验,然后将到数据空间的映射表示为 \(G(z;θ_g)\),其中 \(G\) 是一个可微函数,由一个参数为 \(\theta_g\) 的多层感知器表示。我们还定义了第二个多层感知器 \(D(x; θ_d)\) 输出单个标量。\(D(x)\) 表示 \(x\) 来自数据而不是 \(p_g\) 的概率。
我们训练 \(D\), 以最大化为训练样例和 \(G\) 的样本分配正确标签的概率,即我们期望无论是训练样本还是生成器产生的生成样本,我们都希望 \(D\) 能够将这些样本归属到正确的标签上。
我们同时训练 \(G\) 以最小化 \(log(1- D(G(z)))\):
换句话说,\(D\) 和 \(G\) 以价值函数 \(V(G,D)\) 进行如下的二人极大极小博弈。
\[\begin{gather*} \min\limits_{G} \max\limits_{D} V(D,G) = \mathbb{E}_{x\sim p_{data}(x)}[log\ D(x)] + \mathbb{E}_{z\sim p_{z}(x)}[log(1-D(G(z)))] \end{gather*}\]
对于 \(D\) 而言,我们希望 \(V\) 达到最大,即 \(log\ D(x)\) 和 \(log(1-D(G(z)))]\) 达到最大。前一项代表我们希望判别器能够把训练样本分配为"真实的",后一项代表我们希望判别器能够把来自于生成器的样本分类为"虚假的"。
对于 \(G\) 而言,我们希望 \(V\) 达到最小,即 \(log(1- D(G(z)))\) 达到最小,即 \(D(G(z))\) 达到最大。代表我们期望生成器生成的样本输入到判别器的时候,判别器会将其判别为真实样本,达到成功 "欺骗" 判别器的目的。
3. Algorithm
生成对抗网络的小批量随机梯度下降训练。应用于鉴别器的步数 \(k\) 是一个超参数。代表了先训练 \(k\) 步判别器,再训练 \(k\) 步生成器,一般 \(k=1\)。

4. Global Optimality of \(p_g=p_{data}\)
对于给定的生成器 \(G\),考虑最优的判别器 \(D\)

注意现在 \(D\) 的训练目标可以解释为最大化估计条件概率 \(P(Y = y|x)\) 的对数似然,其中 \(Y\) 表示 $x $是来自 \(p_{data}(Y = 1)\) 还是 \(p_g (Y = 0)\)。现在,Eq. 1中的极大极小博弈可以重新表述为:
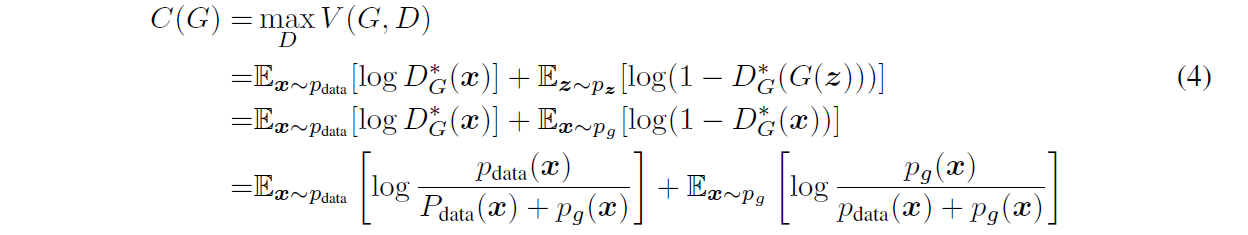
Theorem 1 表示对于我们的训练标准 \(C\) 的全局最小值,仅在 \(p_g=p_{data}\) 的时候达到,并且这个最小值为 \(-log4\)。
证明:如果 \(p_g=p_{data}\),即真实分布和预测分布是一样的,此时最优的 \(D^*_G(x) =\frac{1}{2}\),替换到公式4中,得到 \(C(G)=log\frac{1}{2} + log\frac{1}{2}=-log4\) 。此时如果我们对 \(C(G)\) 减去一个 \(-\log4\) 再加上一个 \(-\log4\)得到:
\[\begin{gather*} \begin{aligned} C(G) &= \mathbb{E}_{x\sim p_{data}}\left[ \log {\frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)} } \right]+\mathbb{E}_{x\sim p_g}\left[ \log {\frac{p_{g}(x)}{p_{data}(x)+p_{g}(x)} } \right] + log4 -\log4 \\ &= \mathbb{E}_{x\sim p_{data}}\left[ \log {\frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)} }+\log2 \right]+\mathbb{E}_{x\sim p_g}\left[ \log {\frac{p_{g}(x)}{p_{data}(x)+p_{g}(x)} } +\log2 \right]-\log4\\ &= \sum \limits_{x \in X}p_{data}(x) \left[ \log \left ( p_{data} \cdot \frac{2}{p_{data}(x)+p_g(x)} \right) \right] + \sum \limits_{x \in X}p_{g}(x) \left[ \log \left ( p_{g} \cdot \frac{2}{p_{data}(x)+p_g(x)} \right) \right] - \log 4 \end{aligned} \end{gather*}\]
根据 \(KL散度\) 的公式:
\[\begin{gather*} D_{KL}(P\ ||\ Q)=\sum\limits_{x\in X}P(x)\log\left ( \frac{P(x)}{Q(x)} \right ) \end{gather*}\]
得到:
\[\begin{gather*}C(G) =-\log(4) + KL \left( p_{data} \parallel \frac{p_{data}+p_{g}}{2} \right) + KL \left( p_{g} \parallel \frac{p_{data}+p_{g}}{2} \right)\end{gather*}\]
\(KL散度\) 一定是 \(\ge0\) 的,因此从公式也可以看出 \(C(G)\) 的最小值为 \(-\log4\).
之后可以根据 \(Jensen-Shannon散度\) 公式:
\[\begin{gather*}JSD(P\ ||\ Q)=\frac{1}{2}D(P||M)+\frac{1}{2}D(Q||M) \ where \ M= \frac{1}{2}(P+Q)\end{gather*}\]
进一步化简得到:
\[\begin{gather*}C(G)=-\log4+2\cdot JSD(p_{data}||p_{g}) \end{gather*}\]

GAN原文链接: https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf