VAE
1. 自编码器 AutoEncoder
无监督的特征学习,其目标是利用无标签数据找到一个有效的低维的特征提取器:
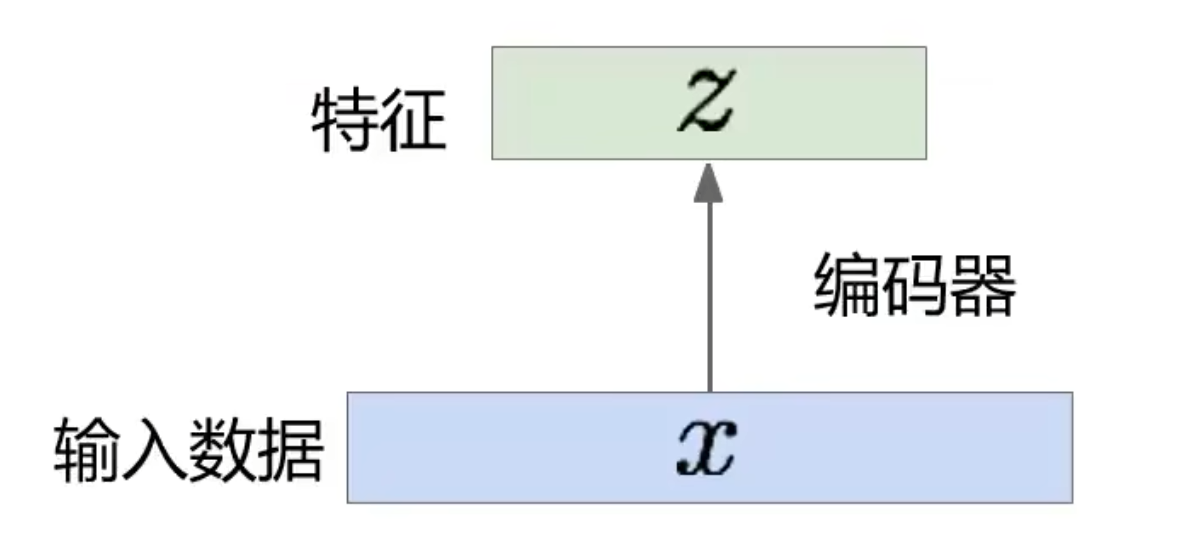
z 的维度一般小于 x 的维度(特征降维)。
Q: 特征降维有什么用? A: 希望降维后的特征仅保留数据中有意义的信息。
如何学习?
自编码利用重构损失来训练低维的特征表示。
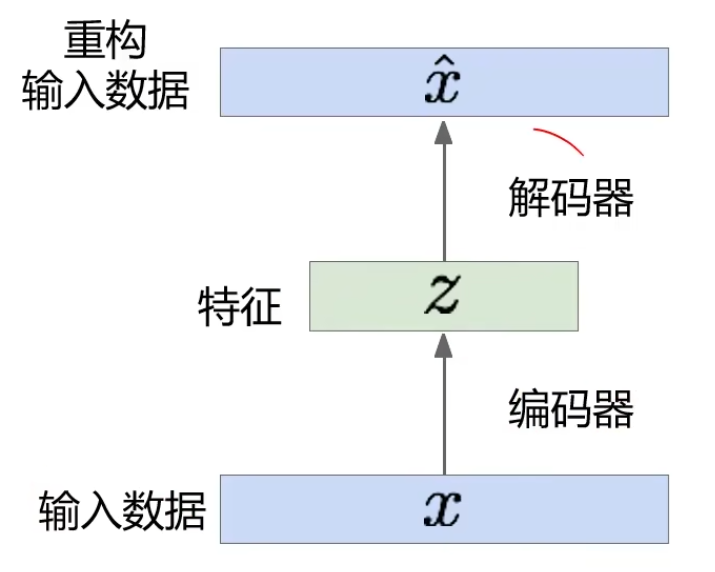
我们希望编码器编出来的特征 \(z\) 通过解码器后生成的 \(\hat x\) 与输入的 \(x\) 越接近越好。
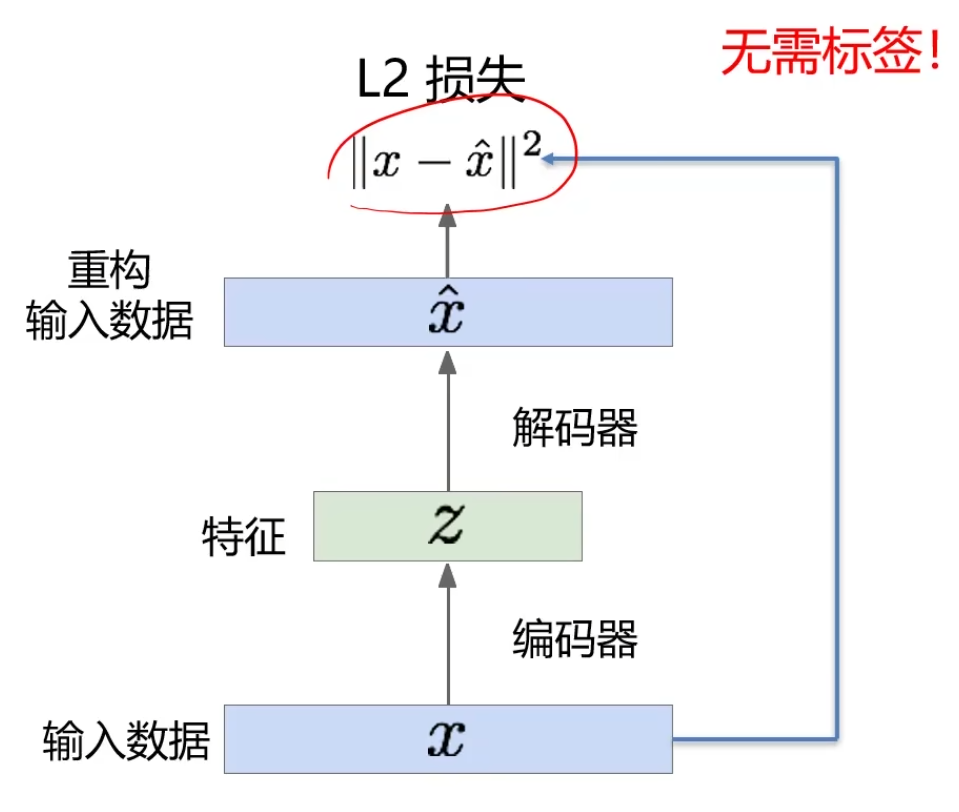
把L2损失当做我们监督的信息,将 \(\hat x\) 与 \(x\) 比,差异大则调整编码器和解码器。在这个学习过程中不需要标签,因此是一个无监督的过程。
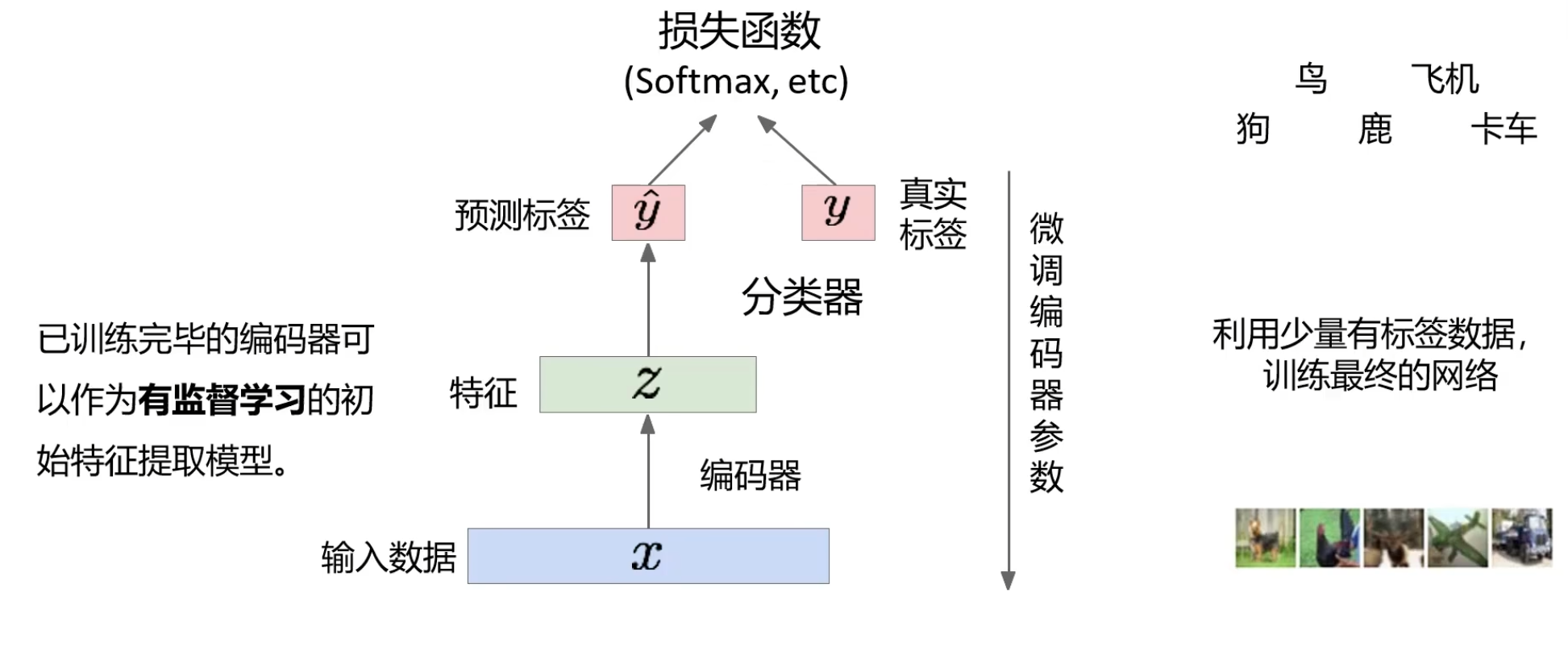
训练后移出解码器,使用 \(z\) 接一个全连接神经网络就可以预测标签,与真实标签做比较,来微调编码器。\(x\) 保留的核心重要的特征对分类起到很大帮助。实现无监督的特征编码器在少样本的时候也能获得分类预测标签。
但是事实证明效果一般,因为对于分类任务来说记住所有特征不代表能做好分类。例如,对于人张三和李四的区分点或许就在一个痣,保留的关键特征或许会记住整个人脸,但是不一定会保留痣,而痣恰好是分类的关键。
解码器
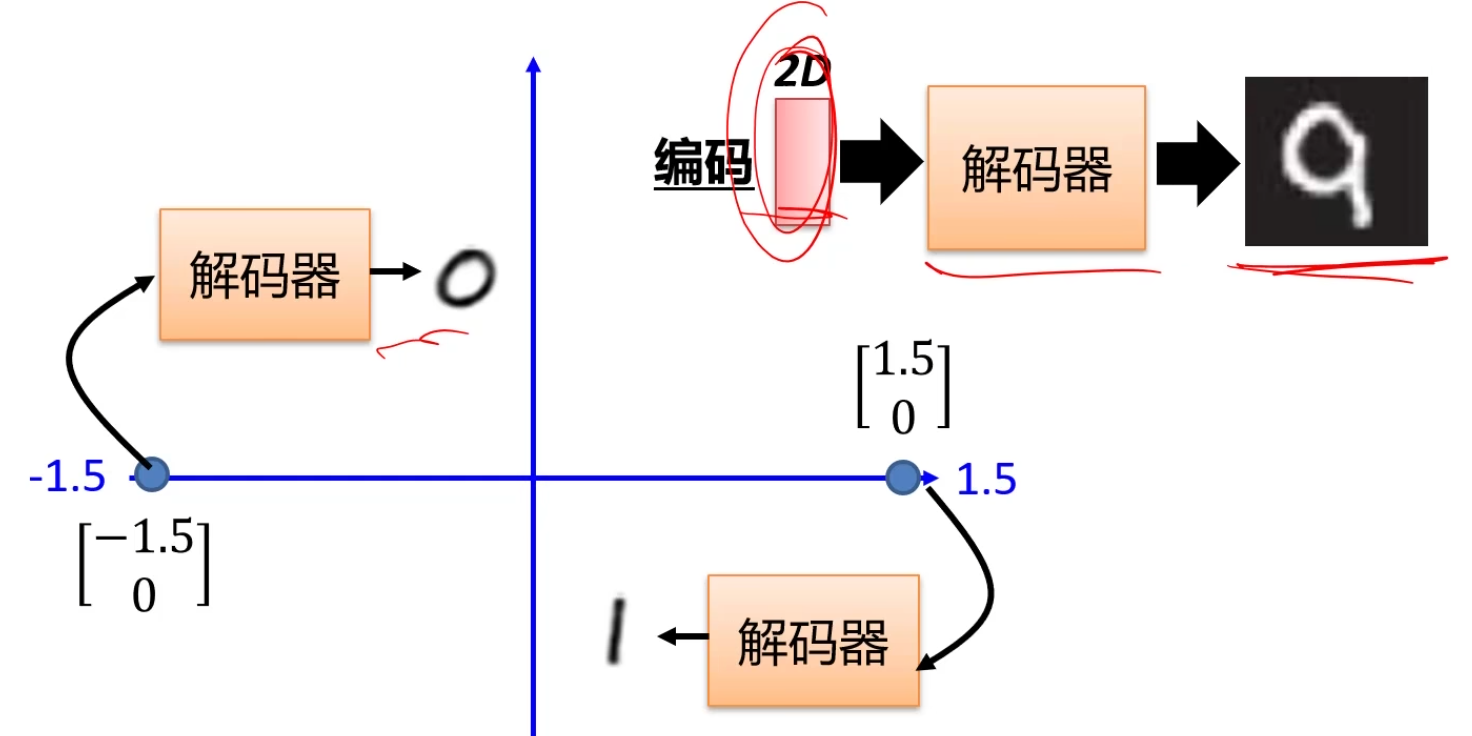
编码器可以用作图像分类任务,而解码器可以用作图像生成:
2. 为什么需要 VAE?(变分自编码器 Variational Autoencoders)
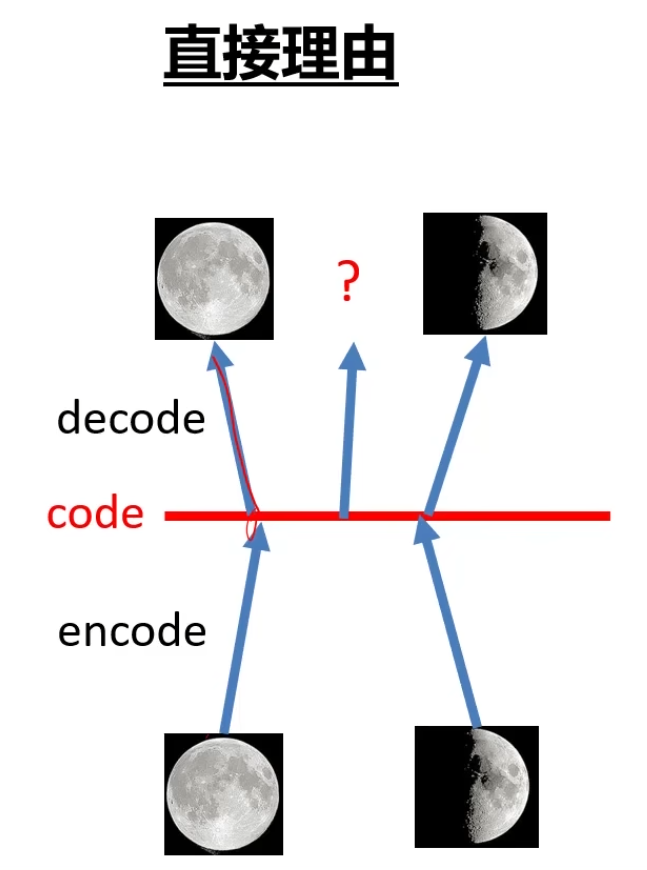
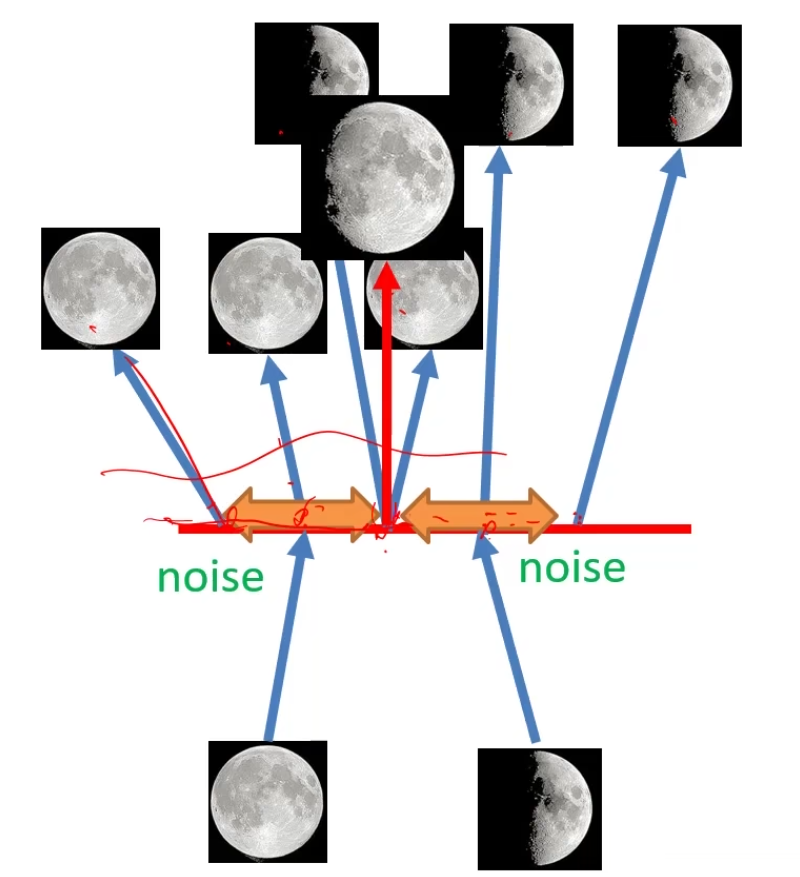
自编码器可以记住码空间的特征关系,但是对于中间部分无法实现。
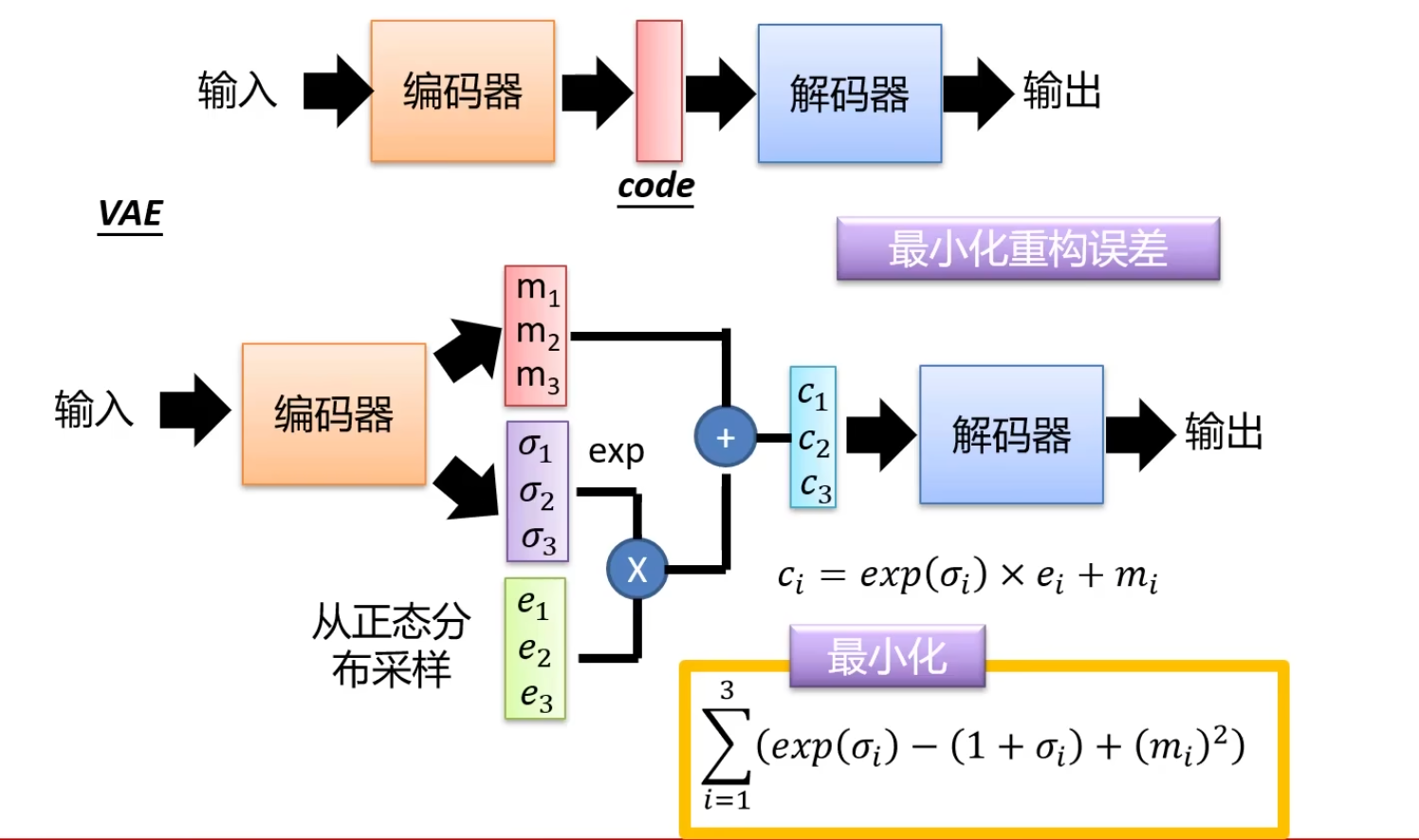
编码器不再输出码 \(z\),而是生成码 \(m\) 加上一个方差 \(\sigma\),\(e\) 为噪声。现在给一张图生成的不是一个 \(z\) 而是一个分布。当需要用码生成图像的时候,会采样这个分布,从而生成图像输出。
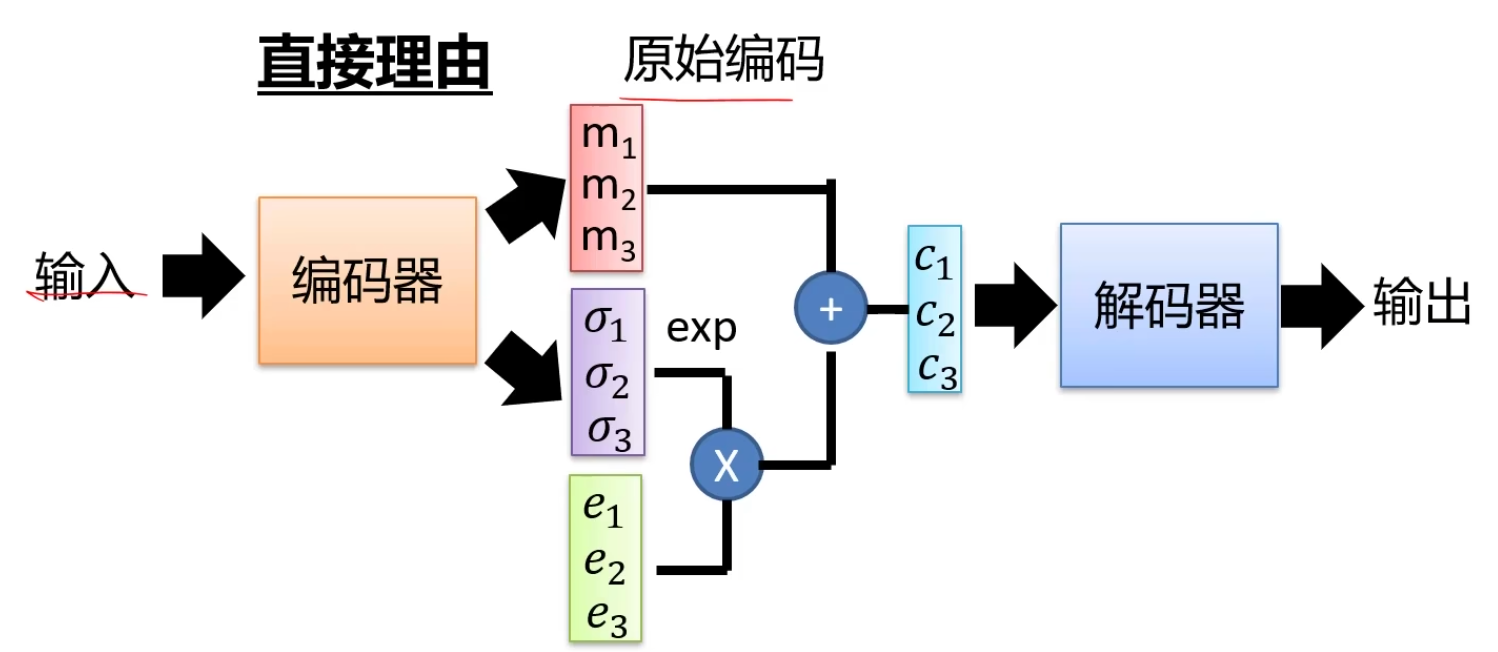
噪声的方差是从数据中学到的,指数次方后一定是个正数,采样:\(z = m_1 + exp(\sigma_1)e_1\)