LSGAN
Least Squares Generative Adversarial Networks
常规 GAN 假设判别器是具有 sigmoid 交叉熵损失函数的分类器。然而,我们发现这种损失函数可能导致学习过程中梯度消失的问题。为了克服这个问题,提出了最小二乘生成对抗网络(LSGANs),该网络对判别器采用最小二乘损失函数
1. GAN
将判别器看作分类器,原始GAN采用 sigmoid 交叉熵损失函数。当更新生成器时,这个损失函数会导致在决策边界正确一侧的样本的梯度消失,但仍然远离真实数据。
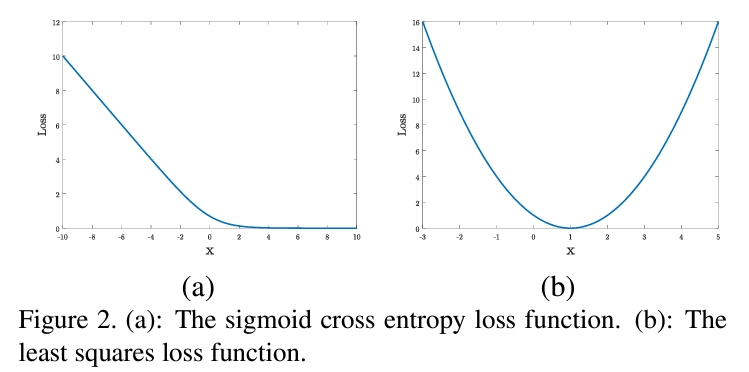
图(a)中显示了sigmoid 交叉熵损失函数的图像,从图中可以观察到当 x>2 之后斜率已经接近与 0,当 x 再变大后 loss 基本已经饱和,梯度一直处在 0 的位置,不利于更新。可以用以下代码验证图像
1 | import torch |
2. LSGAN
为了解决这个问题,我们提出了 Least Squares Generative Adversarial Networks (LSGANs)。假设我们使用 \(a\) - \(b\)编码方案作为鉴别器,其中 \(a\) 和 \(b\) 分别是假数据和真实数据的标签。那么 LSGANs 的目标函数可以定义为: \[ \begin{align} \min\limits_{D} V_{LSGAN}(D) &= \frac{1}{2} \mathbb{E}_{x\sim p_{data}(x)}[(D(x)-b)^2] + \frac{1}{2} \mathbb{E}_{z\sim p_{z}(z)}[(D(G(z))-a)^2]\\ \min\limits_{G} V_{LSGAN}(G) &= \frac{1}{2} \mathbb{E}_{z\sim p_{z}(z)}[(D(G(z))-c)^2] \end{align} \tag{1} \] 其中 \(c\) 表示 \(G\) 希望 \(D\) 相信的假数据值。
3. Relationto \(Pearson \ χ^2 \ Divergence\)
在原始的GAN中已经推导出了: \[ \begin{gather*}C(G) =-\log(4) + KL \left( p_{data} \parallel \frac{p_{data}+p_{g}}{2} \right) + KL \left( p_{g} \parallel \frac{p_{data}+p_{g}}{2} \right)\end{gather*} \tag{2} \] 对于 \((1)\) 做以下修改,在 \(\min\limits_{G} V_{LSGAN}(G)\) 添加 \(\mathbb{E}_{x\sim p_{data}(x)}[(D(x)-c)^2]\) 项,由于此项与 \(G\) 是无关的所以不会产生改变: \[ \begin{align} \min\limits_{D} V_{LSGAN}(D) &= \frac{1}{2} \mathbb{E}_{x\sim p_{data}(x)}[(D(x)-b)^2] + \frac{1}{2} \mathbb{E}_{z\sim p_{z}(z)}[(D(G(z))-a)^2]\\ \min\limits_{G} V_{LSGAN}(G) &= \frac{1}{2} \mathbb{E}_{x\sim p_{data}(x)}[(D(x)-c)^2] + \frac{1}{2} \mathbb{E}_{z\sim p_{z}(z)}[(D(G(z))-c)^2] \end{align} \tag{3} \] 将 \(G(z)\) 改写成 \(x\),则有 \[ \begin{align} \min\limits_{D} V_{LSGAN}(D) &= \frac{1}{2} \mathbb{E}_{x\sim p_{data}(x)}[(D(x)-b)^2] + \frac{1}{2} \mathbb{E}_{x \sim p_{g}(x)}[(D(x)-a)^2] \tag{4} \end{align} \] 当固定生成器 \(G\) 的时候,最优的判别器 \(D\) 为: \[ \begin{align} D^*(x) = \frac{bp_{data}(x)+ap_{g}(x)}{p_{data}(x)+p_{g}(x)} \tag{5} \end{align} \] 我们用 \(p_d\) 表示 \(p_{data}\),由公式\((4)\) 可得: \[ \begin{align} 2C(G) &= \mathbb{E}_{x\sim p_{d}}[(D^*(x)-c)^2] + \mathbb{E}_{z\sim p_{z}}[(D^*(G(z))-c)^2] \\ &= \mathbb{E}_{x\sim p_{d}}[(D^*(x)-c)^2] + \mathbb{E}_{x\sim p_{g}}[(D^*(x)-c)^2] \\ &= \mathbb{E}_{x\sim p_{d}}[(\frac{bp_{d}(x)+ap_{g}(x)}{p_{d}(x)+p_{g}(x)}-c)^2] + \mathbb{E}_{x\sim p_{g}}[(\frac{bp_{d}(x)+ap_{g}(x)}{p_{d}(x)+p_{g}(x)}-c)^2] \\ &= \int_{x}p_d(x)(\frac{(b-c)p_d(x)+(a-c)p_g(x)}{p_{d}(x)+p_{g}(x)})^2dx + \int_{x}p_g(x)(\frac{(b-c)p_d(x)+(a-c)p_g(x)}{p_{d}(x)+p_{g}(x)})^2 dx \\ &= \int_{x}\frac{((b-c)p_d(x)+(a-c)p_g(x))^2}{p_{d}(x)+p_{g}(x)} dx \\ &= \int_{x}\frac{((b-c)(p_d(x)+p_g(x))-(b-a)p_g(x))^2}{p_{d}(x)+p_{g}(x)} dx \tag{6} \end{align} \] 如果 \(b-c=1\),\(b-a =2\),那么: \[ \begin{align} 2C(G) &= \int_{x}\frac{(2p_g(x)-(p_d(x)+p_g(x)))^2}{p_{d}(x)+p_{g}(x)} dx \tag{6} \\ &= X^2_{Pearson}(p_d + p_g||2p_g) \end{align} \] \(X^2_{Pearson}\) 为 \(Pearson散度\)。
因此,当满足 $b−c=1 $ 和\(b−a=2\) 时,最小化方程 \((4)\) 即为最小化 \(p_d + p_g\) 和 \(2p_g\) 之间的 \(Pearson散度\)。
4. ParametersSelection
当设置 \(a=-1,b=1, c=0\),则有 \[ \begin{align} \min\limits_{D} V_{LSGAN}(D) &= \frac{1}{2} \mathbb{E}_{x\sim p_{data}(x)}[(D(x)-1)^2] + \frac{1}{2} \mathbb{E}_{z\sim p_{z}(z)}[(D(G(z))+1)^2]\\ \min\limits_{G} V_{LSGAN}(G) &= \frac{1}{2} \mathbb{E}_{z\sim p_{z}(z)}[(D(G(z)))^2] \end{align} \tag{7} \] 另一种方法可以设置 \(c=b\),则有 \[ \begin{align} \min\limits_{D} V_{LSGAN}(D) &= \frac{1}{2} \mathbb{E}_{x\sim p_{data}(x)}[(D(x)-1)^2] + \frac{1}{2} \mathbb{E}_{z\sim p_{z}(z)}[(D(G(z)))^2]\\ \min\limits_{G} V_{LSGAN}(G) &= \frac{1}{2} \mathbb{E}_{z\sim p_{z}(z)}[(D(G(z))-1)^2] \end{align} \tag{8} \] 实践中 \((7)\) 和 \((8)\) 效果类似